puppeteer无头浏览器体验小爬
介绍
Puppeteer 是一个 Node 库,它提供了高级的 API 并通过 DevTools 协议来控制 Chrome(或Chromium),即一个无头浏览器,
看不到UI,但是能进行浏览器的一些操作。(也可以设置成非无头)
简单使用
直接上手,后面再解释一下下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import puppeteer from "puppeteer";
(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
args: ['--start-maximized']
});
const baseUrl = 'https://juejin.cn';
const page = await browser.newPage();
await page.goto(baseUrl);
const latestBtn = await page.waitForSelector('.entry-list-container .nav-list li:nth-child(2) a');
await latestBtn.click();
const article = await page.waitForSelector('.entry-list > li:nth-child(2)');
const author = await article.evaluate((el, baseUrl) => {
const userInfo = {
nickname: el.querySelector('.user-message .user-popover').textContent.trim(),
url: `${baseUrl}${el.querySelector('.user-message').getAttribute('href')}`
};
console.log(userInfo);
return userInfo;
}, baseUrl);
console.log(author);
})();
|
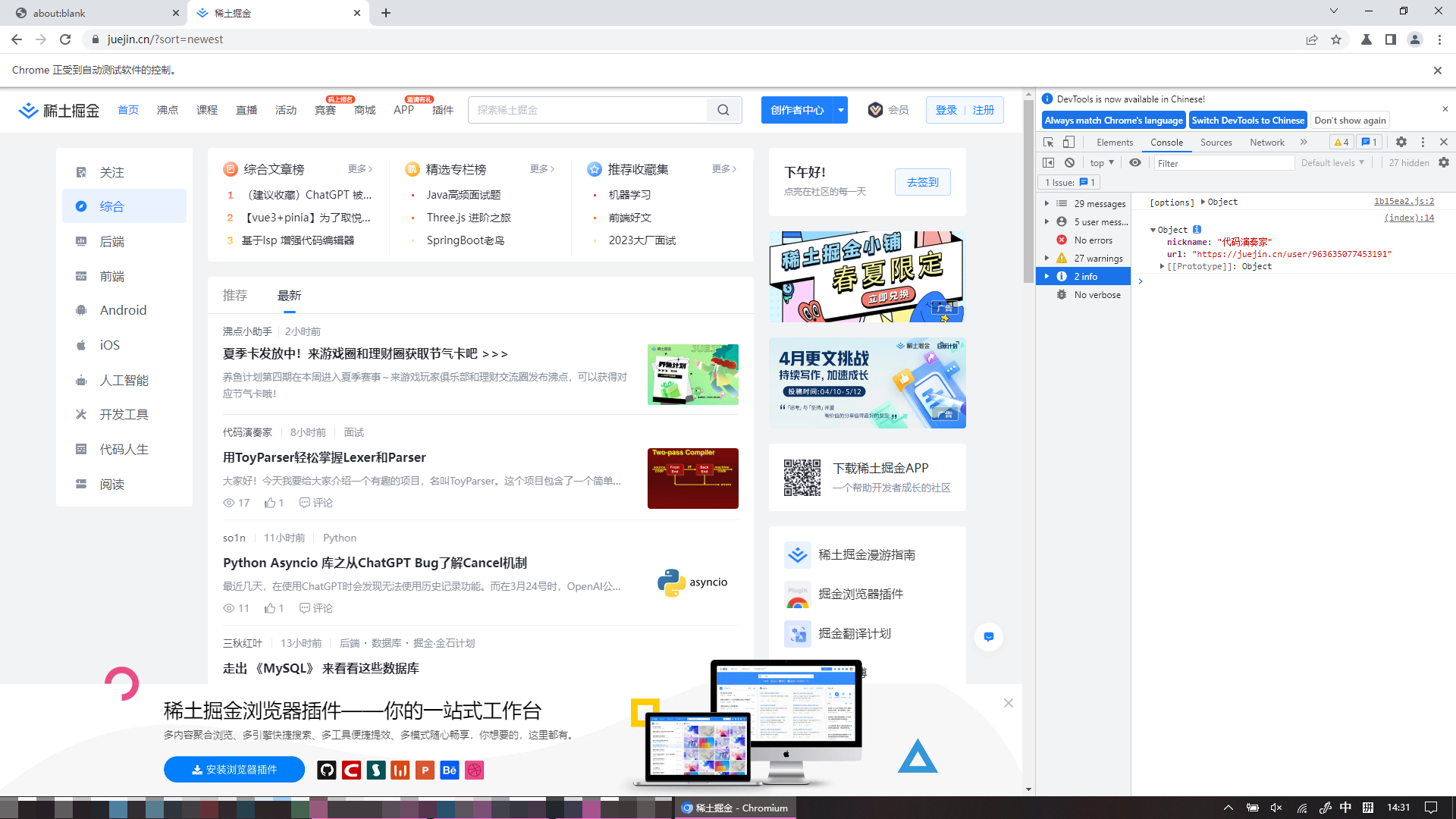
启动直接打开获取最新文章的作者信息,并且启动node的终端也会打印对应信息。
1. 启动浏览器
1
2
3
4
5
| const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
args: ['--start-maximized']
});
|
通过puppeteer.lauch启动浏览器,并且通过参数来配置。
headless:是否是无头,默认是true。如果是true,则不会以可见形式形式打开浏览器。(简单来说就是任务栏看不到,但是也能做到一样的行为)
defaultViewport:默认视口,视口是有一个默认值的,这样会导致打开的页面不是全屏,所以要设置一下。
args:添加参数,添加参数,实现窗口在浏览器中最大化。
2. 打开新页面,并前往指定链接
1
2
3
4
| const baseUrl = 'https://juejin.cn';
const page = await browser.newPage();
await page.goto(baseUrl);
|
看上面的效果图,就可以发现:打开了两个标签页。因为打开浏览器默认会打开一个标签页,而通过brower.newPage()则又会打开一个标签页。
如果想要得到只有一个标签页的效果的话,那就可以使用brower.pages()获取所有的标签页,然后让第一个标签页前往指定链接。(因为刚刚打开的浏览器默认只有一个标签页)
1
2
| const [page] = await browser.pages();
await page.goto(baseUrl);
|
3. 通过选择器获取DOM元素,并点击
1
2
| const latestBtn = await page.waitForSelector('.entry-list-container .nav-list li:nth-child(2) a');
await latestBtn.click();
|
通过使用page.waitForSelector()来获取符合指定选择器的第一个DOM元素。也是需要使用await来获取的,更准确来说,puppeteer的操作基本都是异步的。这个waitForSelector就是需要等到页面加载出这个元素后才获取。
4. 大杀器evaluate:在浏览器中执行代码,并在node中获取返回值
1
2
3
4
5
6
7
8
9
10
| const article = await page.waitForSelector('.entry-list > li:nth-child(2)');
const author = await article.evaluate((el, baseUrl) => {
const userInfo = {
nickname: el.querySelector('.user-message .user-popover').textContent.trim(),
url: `${baseUrl}${el.querySelector('.user-message').getAttribute('href')}`
};
console.log(userInfo);
return userInfo;
}, baseUrl);
|
evaluate()内编写的代码,会在浏览器中执行。并且它的返回值可以在node中获取到。evaluate()方法的函数参数是没办法访问外部变量的,所以如果需要访问外部变量,需要像上面一样,将外部变量作为第二个参数传递。
\color{red}{evaluate接收的参数和返回值都得是可序列化为JSON的}。所以如果传参或者返回值包括函数等不可序列化为JSON的就会接收不到数据。
5. 关闭浏览器
6. 额外技能page.exposeFunction
我们上面是通过使用evaluate方法时,return一个返回值来实现在node中得到一些数据。但是我们还可以通过page.exposeFunction()来暴露一个函数,暴露的函数会被插入到window对象中,所以在evaluate中调用暴露的这个方法就能实现直接获取参数数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| await page.exposeFunction('getInfo', (userInfo, articleInfo) => {
console.log(userInfo, articleInfo);
});
const article = await page.waitForSelector('.entry-list > li:nth-child(2)');
await article.evaluate((el, baseUrl) => {
const userInfo = {
nickname: el.querySelector('.user-message .user-popover').textContent.trim(),
url: `${baseUrl}${el.querySelector('.user-message').getAttribute('href')}`
};
const articleInfo = {
name: el.querySelector('.title-row .title').textContent.trim(),
url: `${baseUrl}${el.querySelector('.title-row .title').getAttribute('href')}`
}
window.getInfo(userInfo, articleInfo);
}, baseUrl);
|
使用自带浏览器
使用puppeteer默认是会使用自带的一个无头浏览器,启动后,它的图标和Chrome的也不太一样,那么能不能使用本地安装好的Chrome呢?通过executablePath属性配置Chrome路径即可。
如果使用本地安装好的Chrome的话,那就可以直接使用puppeteer-core,而不是puppeteer。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import puppeteer from "puppeteer-core";
import findChrome from 'carlo/lib/find_chrome.js';
(async () => {
const chromePath = await findChrome({});
const browser = await puppeteer.launch({
executablePath: chromePath.executablePath,
headless: false,
defaultViewport: null,
args: ['--start-maximized']
});
})();
|
上面用到了carlo的findChrome方法来查找Chrome的路径。
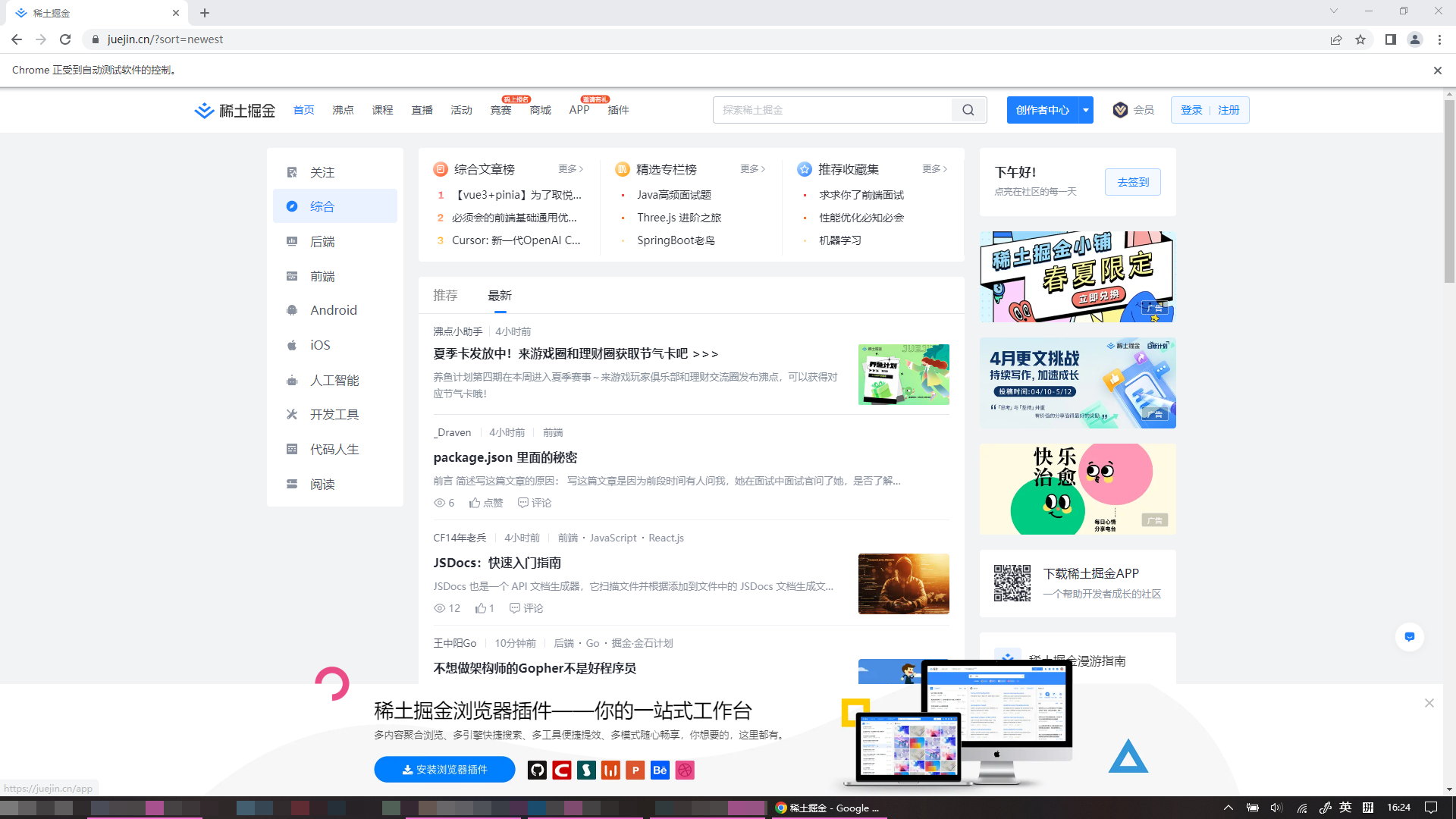
使用浏览器的数据
按上面的方法使用自带浏览器后,浏览器的登录状态、掘金的登录状态等都是没有的。最后找到了两个解决方案。
使用userDataDir属性
首先,需要需要找到个人资料的文件夹,可以通过访问chrome://version,来获取。
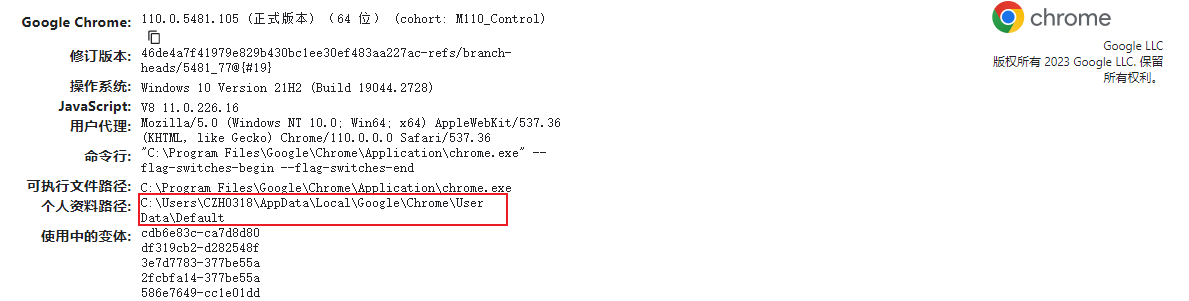
不需要default。
\color{red}{要和executablePath一起使用}
如果使用puppeteer而不是puppeteer-core,并且没有配置executablePath,配置了userDataDir,会导致一些数据丢失。比如一些网站的登录状态、扩展程序也会因为丢失数据而损坏(需要修复,基本相当于重装)
猜测应该是设置userDataDir后,打开浏览器的一些数据会覆盖掉之前的数据,所以就会导致数据丢失。
并且使用userDataDir属性的方式没办法在已经启动浏览器的状态下运行,无头模式倒是可以,不清楚原因。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import puppeteer from "puppeteer-core";
import findChrome from 'carlo/lib/find_chrome.js';
(async () => {
const chromePath = await findChrome({});
const browser = await puppeteer.launch({
executablePath: chromePath.executablePath,
userDataDir: 'C:/Users/CZH0318/AppData/Local/Google/Chrome/User Data',
headless: false,
defaultViewport: null,
args: ['--start-maximized']
});
})();
|
puppeteer.connect连接浏览器
开始之前,需要让Chrome打开指定调试端口。通过修改Chrome的快捷方式来实现。
在目标后面添加--remote-debugging-port=9222
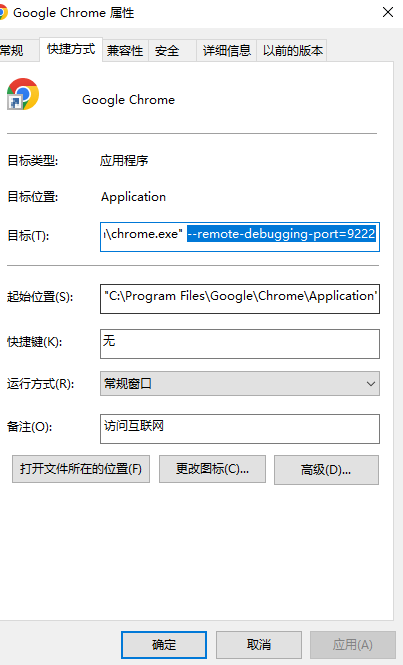
之后通过双击快捷方式文件打开浏览器,并且访问http://127.0.0.1:9222/json/version(测试用任务栏打开时无效的)
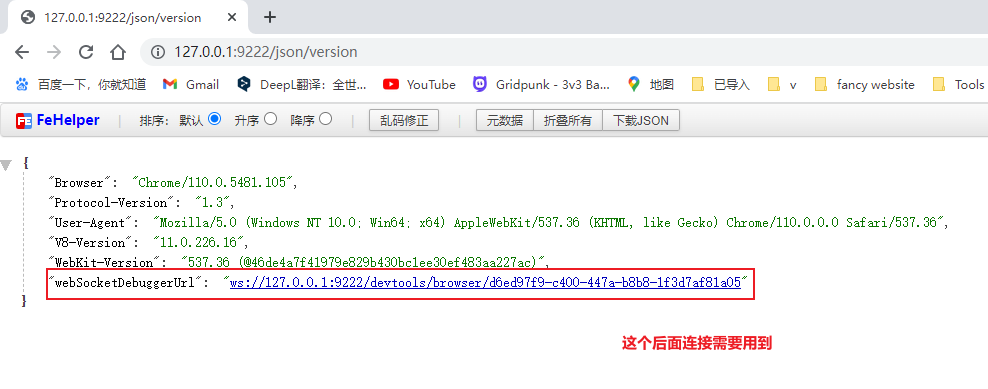
将上面红框框住的值作为browserWSEndpoint属性值传给connect方法。
1
2
3
4
5
6
| const browser = await puppeteer.connect({
browserWSEndpoint: "ws://127.0.0.1:9222/devtools/browser/c1d56b5d-48b0-4da2-b55b-f36b7e1ea66f",
headless: false,
defaultViewport: null,
args: ['--start-maximized']
});
|
这个方法的好处是在已经启动浏览器的状态下运行,但是也不能通过手动方式打开,因为只有通过快捷方式打开才行。而且重新打开浏览器,ws连接也会变。
所以如果有对应需求,还是建议使用userDataDir的方式
参考及更多
GitHub - puppeteer/puppeteer: Headless Chrome Node.js API
puppeteer issues 3543
Connecting Puppeteer to Existing Chrome
无头浏览器 Puppeteer 初探 - 掘金



